A managed cluster platform that simplifies running big data frameworks, such as Apache Hadoop and Apache Spark, on AWS to process and analyze vast amounts of data.
It lets you transform and move large amounts of data into and out of other AWS data stores and databases, such as Amazon Simple Storage Service (Amazon S3) and Amazon DynamoDB.
Architecture
The central component of Amazon EMR is the cluster.
A cluster is a collection of Amazon Elastic Compute Cloud (Amazon EC2) instances.
Each instance in the cluster is called a node. Each node has a role within the cluster, referred to as the node type.
Amazon EMR also installs different software components on each node type, giving each node a role in a distributed application like Apache Hadoop.
All EMR clusters, including high-availability clusters, are launched in a single Availability Zone.
Node Types:
Primary node
manages the cluster
runs software components to coordinate the distribution of data and tasks among other nodes for processing
tracks the status of tasks and monitors the health of the cluster
it’s possible to create a single-node cluster with only the primary node
Core node
has software components that run tasks and store data in the Hadoop Distributed File System (HDFS)
Multi-node clusters have at least one core node.
Can resize a running core node.
Can add or remove core node but with a risk of losing data.
AWS EMR will automatically provision if a core node fails.
Runs YARN NodeManager daemons, Hadoop MapReduce tasks, and Spark executors.
Task node
runs software components that only run tasks and do not store data in HDFS.
Task nodes are optional.
Can remove task nodes on the fly.
Cluster Scaling:
Automatic Scaling:
Two options:
Custom Scaling
You need to define and manage the automatic scaling policies and rules,
Instance groups only
Based on CW metrics
Programmatically scale out and scale in core nodes and task nodes based on a CloudWatch metric and other parameters that you specify in a scaling policy
You can define the evaluation periods only in five-minute increments.
You can choose which applications are supported
Managed Scaling
No policy is required. Amazon EMR manages the automatic scaling activity.
Increase or decrease the number of instances or units in your cluster based on workload.
Instance groups or instance fleets
Only YARN applications are supported, such as Spark, Hadoop, Hive, Flink.
Manual Scaling
Add and remove instances manually from core and task instance groups and instance fleets in a running cluster.
Service Architecture Layer:
Storage
Different file systems are used with your cluster.
Hadoop Distributed File System (HDFS) :
A distributed, scalable file system for Hadoop
Multiple copies of data across instances.
Ephemeral, i.e. data will be lost when the cluster is shut down.
You can use S3DistCP to efficiently copy large amounts of data from Amazon S3 into HDFS where subsequent steps in your Amazon EMR cluster can process it
EMR File System (EMRFS):
Extends Hadoop to add the ability to directly access data stored in Amazon S3 as if it were a file system like HDFS
Persistent
Local file system – An Amazon EC2 preconfigured block of pre-attached disk storage called an instance store
Cluster resource management
Manages cluster resources and scheduling the jobs for processing data.
By default, Amazon EMR uses YARN (Yet Another Resource Negotiator)
Other frameworks and applications that are offered in Amazon EMR that do not use YARN as a resource manager.
Data processing frameworks
The engine used to process and analyze data.
The main processing frameworks available are:
Hadoop MapReduce
Apache Spark
Applications and programs
Supports many applications such as Hive, Pig, and the Spark Streaming library
Cluster Termination
3 Ways to Shutdown Cluster
Termination after the last step of execution
a transient cluster that shuts down after all steps are complete.
the cluster starts, runs bootstrap actions, and then runs the steps that you specify. As soon as the last step completes, Amazon EMR terminates the cluster’s Amazon EC2 instances.
Auto-termination (after idle)
auto-termination policy that shuts down after a specified idle time.
You specify the amount of idle time after which the cluster should automatically shut down.
Manual termination
is a long-running cluster that continues to run until you terminate it deliberately.
Serverless EMR
A deployment option for Amazon EMR that provides a serverless runtime environment.
You don’t have to configure, optimize, secure, or operate clusters to run applications like Spark, Hive or Presto.
Avoid over- or under-provisioning resources for your data processing jobs.
It automatically determines the resources that the application needs, obtains these resources to process your jobs, and releases the resources when the jobs finish.
You can provide a pre-initialized capacity that keeps workers initialized and ready to respond in seconds.
Make sure to add 10% in your initial capacity because Spark adds 10% overhead.
Running Jobs:
Create an EMR Serverless application (CLI or EMR Studio)
Submit a job run (CLI or use notebooks that are hosted in EMR Studio to run interactive workloads)
EMR on EKS
A deployment option for Amazon EMR that allows you to run open-source big data frameworks on Amazon Elastic Kubernetes Service (Amazon EKS).
You can run Amazon EMR based applications with other types of applications on the same Amazon EKS cluster.
Fully managed by AWS.
Spark
Components:
Spark Core
Spark Streaming
Spark MLib
Spark GraphX
Spark SQL
Spark Core:
Performs:
Scheduling, monitoring, and distributing jobs
Fault management
Memory management
Storage interface
Uses RDD (Resilient Distributed Dataset)
Transformation operations create RDD
Action operations process data
Spark Streaming:
Process streamed data in batch or real-time
Input data are broken in batches for processing.
Spark MLib:
Low-level machine learning library
Spark GraphX:
The engine that can handle and process Graph data.
Spark SQL:
The framework that is used to process structured or semi-structured data.
It allows you to work on different data formats.
MapReduce
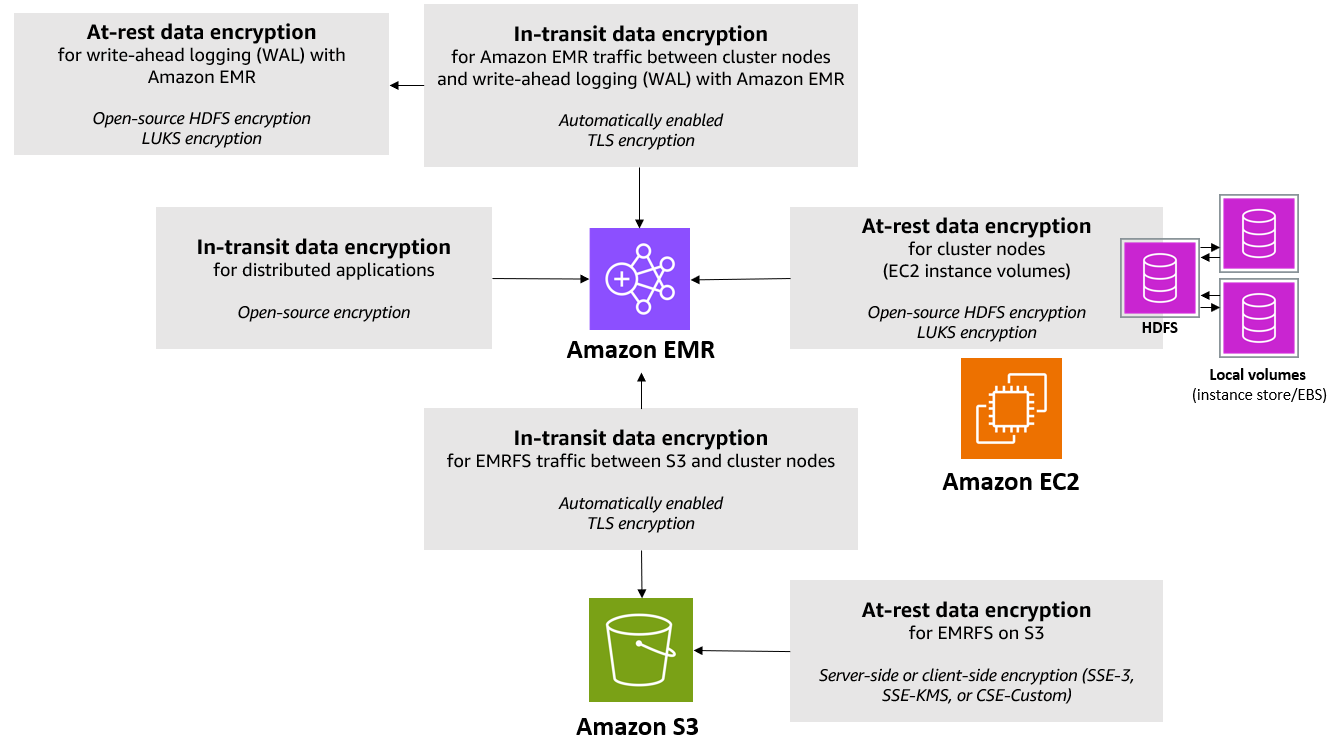
Security
EC2 key pair for SSH
Encryption in transit
Encryption at rest:
EBS volumes
EBS encryption
LUKS (Linux Unified Key Setup) encryption – does not work with root volume)
Open-source HDFS encryption
S3 bucket (EMR by default uses the EMR file system (EMRFS)

{kind=link}