Overview
- A fully managed, petabyte-scale data warehouse service in the cloud.
- Use MPP (Massively Parallel Processing) execution to achieve high performance.
- Multiple compute nodes handle all query processing leading up to final result aggregation, with each core of each node running the same compiled query segments on portions of the entire data.
- Redshift distributes the rows of a table to the compute nodes so that the data can be processed in parallel.
- Designed for OLAP.
- Columnar storage
- Each data block stores values of a single column for multiple rows. As records enter the system, Amazon Redshift transparently converts the data to columnar storage for each of the columns.
- Uses SQL to query data.
- Scale up and down on demand.
- Uses JDBC/ODBC or Data API to connect to the database programmatically.
- It has built-in Backup and Replication
- 2 Types of Redshift:
- Provisioned
- A collection of compute nodes and a leader node, which you manage directly.
- Serverless
- Automatically provisions and manages capacity for you.
- Doesn’t have the concept of a cluster or node.
- Uses Namespace and Workload to isolate workloads and manage different resources
- Automatically manages resources efficiently and scales, based on workloads, within the thresholds of cost controls.
- Provisioned
- Anti-Patterns:
- OLTP
- Small Data
- Unstructured Data
- Blob
Common Use Case
- Data Analytics
- Unified Data Warehouse or Data Lake
- Stock Analysis
- Social Trend Analysis
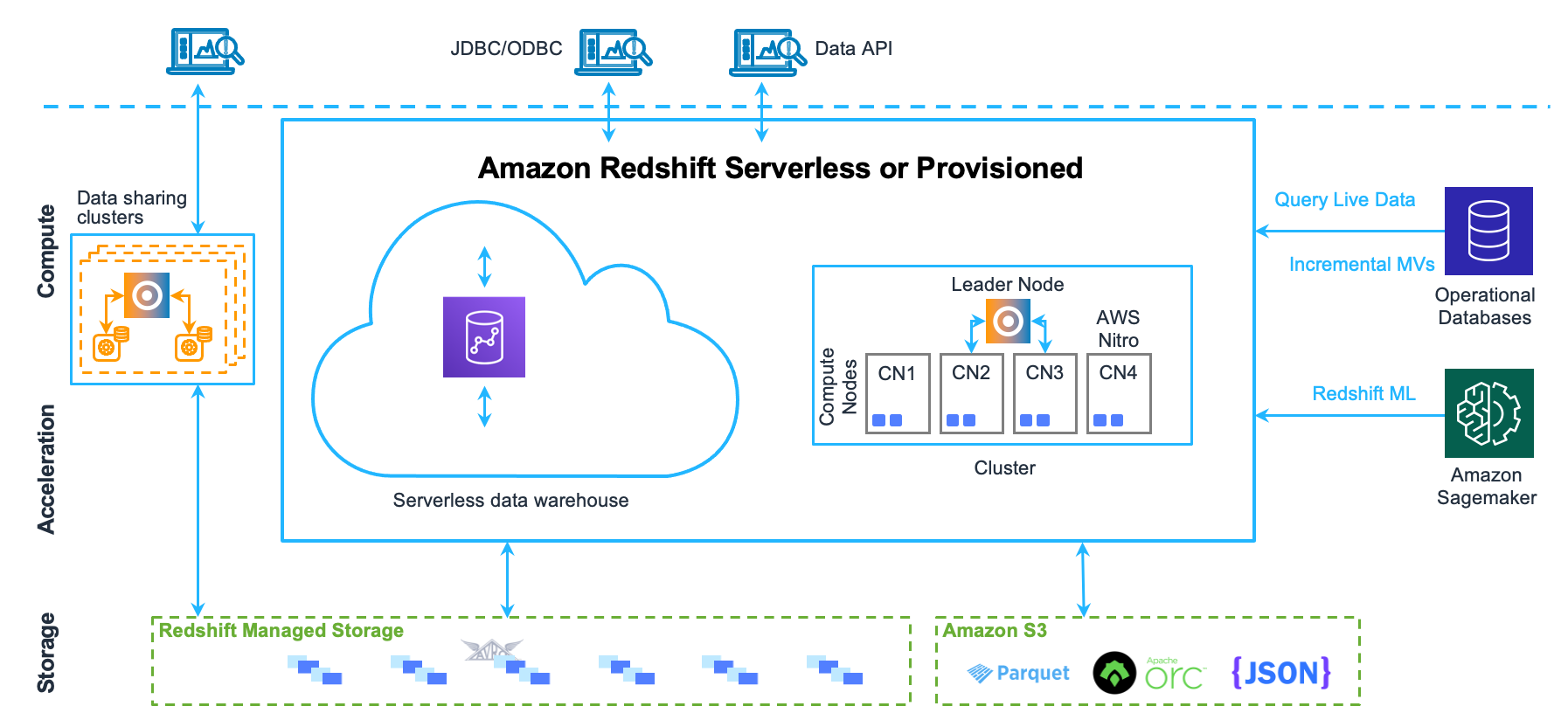
Architecture (Provisioned)
https://docs.aws.amazon.com/images/redshift/latest/dg/images/architecture.png
Components
- Clients:
- Integrates with various data loading and ETL and reporting, data mining, and analytics tools.
- Uses JDBC/ODBC or Data API for connection
- Based on open standard PostgreSQL, most existing SQL client applications will work with minimal changes.
- Only interacts with the leader node.
- Cluster:
- A cluster is composed of one or more compute nodes.
- A cluster can be created in two ways:
- Single Node: The node functions as both leader and compute node
- Mult-Node: An additional leader node will be added to coordinate the compute nodes and handle external communication.
- Leader Node:
- Manages communications with client programs and all communication with compute nodes.
- Based on the execution plan, the leader node compiles code, distributes the compiled code to the compute nodes, and assigns a portion of the data to each compute node.
- The leader node distributes SQL statements to the compute nodes only when a query references tables stored on them.
- Compute Node:
- Run the compiled code and send intermediate results back to the leader node for final aggregation.
- Each compute node has its dedicated CPU and memory, determined by the node type.
- Node Slices:
- A compute node is partitioned into slices.
- Each slice is allocated a portion of the node’s memory and disk space, processing a portion of the workload assigned to the node.
- The node size of the cluster determines the number of slices per node.
- Rows are distributed to the node slices according to the distribution key that is defined for a table
- Node Type:
- Dense Compute (DC): Data is stored in the node
- RA3: Data is stored in Amazon S3, and the local drive is used as a data cache.
- A cluster contains one or more databases.
- User data is stored on the compute nodes.
- Redshift Managed Storage:
- Only available on RA3 Node.
- A separate storage layer apart from the node storage that stores data warehouse data.
- Scale your storage to petabytes using Amazon S3 storage.
- Lets you scale and pay for computing and storage independently.
Durability
- Data is stored in 3 locations within the cluster.
- On the original node
- On a replica of compute nodes
- On S3 as a snapshot
- Snapshots can be taken automatically or manually. They are point-in-time backups of a cluster stored internally in S3.
- Automated snapshots are deleted at the end of a retention period.
- Manual snapshots are retained indefinitely, even after you delete your cluster.
- Can asynchronously replicate the snapshots to S3 in another region for DR.
- Steps to create a cross-region snapshot (only on the provisioned cluster):
- Create a KMS key in the destination region.
- Create a snapshot copy grant in the destination region specifying the KMS key created in Step 1.
- In the source AWS Region, enable copying of snapshots and specify the name of the snapshot copy grant that you created in the destination AWS Region.
- Steps to create a cross-region snapshot (only on the provisioned cluster):
- Amazon Redshift will automatically detect and replace a failed node in your data warehouse cluster.
- The replacement node is made available immediately and loads your most frequently accessed data from Amazon S3 first, allowing you to resume querying your data as quickly as possible.
- Single-node clusters do not support data replication. In the event of a drive failure, you must restore the cluster from a snapshot on S3.
- Single-AZ deployment:
- If the cluster’s Availability Zone becomes unavailable, Amazon Redshift will automatically move it to another AWS Availability Zone (AZ) without any data loss or application changes. You must enable the relocation capability in your cluster configuration settings to activate this.
- Multi-AZ deployment:
- Only for provisioned RA3 clusters.
- It deploys compute resources in two Availability Zones (AZs), which can be accessed through a single endpoint.
- You need to create a mirror and then self-manage replication and failover.
Scaling (Provisioned)
- Automatic:
- Concurrency Scaling
- Vertical scaling
- It is enabled through WLM.
- Automatically adds cluster capacity when your cluster experiences an increase in query queueing.
- Concurrency Scaling
- Manual:
- Elastic Resize
- Horizontal and Vertical scaling
- Add nodes to or remove nodes from your cluster of the same type.
- Change the node type, such as from DC2 nodes to RA3 nodes (this will drop connection)
- Completes quickly, taking ten minutes on average.
- Classic Resize
- It can change the node type, number of nodes, or both, similar to elastic resize.
- It takes more time to complete.
- Handles use cases where the change in cluster size or node type isn’t supported by elastic resize
- Resize Steps:
- A snapshot is created.
- A new target cluster is provisioned with the latest data from the snapshot, and data is transferred to the new cluster in the background. During this period, data is read-only.
- When the resize nears completion, Amazon Redshift updates the endpoint to point to the new cluster and all connections to the source cluster are dropped.
- Elastic Resize
- Snapshot & Restore:
- Near zero downtime.
- A new cluster is provisioned. The old cluster is still running.
- Use the snapshot for the old cluster to restore to the new cluster.
Work Load Management (WLM)
- Manage and prioritize concurrent queries and user workloads to optimize performance and resource utilization.
- It allows you to define queues, user groups, and other constructs to control the resources allocated to different types of queries or users.
- It can be configured to run either automatic or manual.
- Automatic WLM:
- Redshift manages how resources are divided to run concurrent queries with automatic WLM.
- Determines how many queries run concurrently and how much memory is allocated to each dispatched query.
- It’s possible to define query priorities for workloads in a queue.
- Can create up to eight (8) queues with the service class. Each queue has a priority.
- Concurrency is lower when large queries are submitted.
- Concurrency is higher when lighter queries are submitted,
- Automatic WLM is separate from short query acceleration (SQA)
- Manual WLM:
- Not available on Redshift Serverless.
- Manage system performance by creating separate queues for long-running queries and short-running queries.
- Each queue is allocated a portion of the cluster’s available memory.
- Each query queue contains a number of query slots. A queue’s memory is divided among the queue’s query slots.
- By default, Amazon Redshift configures the following query queues:
- One superuser queue
- It is reserved for superusers only, and it can’t be configured.
- Use this queue only when you need to run queries that affect the system or for troubleshooting purposes.
- One default user queue
- Configured to run five queries concurrently.
- The default queue must be the last queue in the WLM configuration.
- Any queries that are not routed to other queues run in the default queue.
- One superuser queue
- You can add up to eight (8) queues to the default queue.
- Queries in a queue run concurrently until they reach the WLM query slot count, or concurrency level, defined for that queue.
- The maximum slot count across all user-defined queues is 50
- Short Query Acceleration (SQA):
- Prioritizes selected short-running queries ahead of longer-running queries.
- Runs short-running queries in a dedicated space.
- Only prioritizes queries that are short-running and are in a user-defined queue.
- CREATE TABLE AS (CTAS) statements and read-only queries, such as SELECT statements, are eligible for SQA.
- It uses a machine learning algorithm to analyze each eligible query and predict its execution time but can define how many seconds is ‘short’.
Table Optimization
Column Compression
- Compression is a column-level operation that reduces the size of data when it is stored.
- Compression conserves storage space and reduces the size of data read from storage, which reduces the amount of disk I/O and, therefore, improves query performance.
- ENCODE AUTO is the table default in which Amazon Redshift automatically manages compression encoding for all columns.
- Avoid compressing the sort key columns
Data Distribution
- When you load data into a table, Amazon Redshift distributes the rows of the table to each of the node slices according to the table’s distribution style.
- Distribution Styles:
- AUTO
- Redshift assigns an optimal distribution style based on the size of the table data.
- Redshift automatically changes the distribution style as the size of the table data grows.
- EVEN
- Distributes the rows across the slices round-robin, regardless of the values in any particular column.
- This style is appropriate when a table doesn’t participate in joins, OR there isn’t a clear choice between KEY distribution and ALL distribution.
- KEY
- The rows are distributed according to the values in one column(the Key).
- Keys with matching hashed values are physically stored together on the same node slice.
- ALL
- A copy of the entire table is distributed to every node.
- ALL distribution multiplies the storage required by the number of nodes in the cluster, so it takes much longer to load, update, or insert data into multiple tables.
- ALL distribution is appropriate only for relatively slow-moving tables, that is, tables that are not updated frequently or extensively.
- AUTO
Sort Keys
- Can alternatively define one or more of its columns as sort keys
- When data is initially loaded into the empty table, the rows are stored on disk in sorted order.
- Sorting enables efficient handling of range-restricted predicates.
- Types of Sort Keys:
- Compound:
- Made up of all of the columns listed in the sort key definition, in the order they are listed.
- It is most useful when a query’s filter applies conditions, such as filters and joins, that use a prefix of the sort keys.
- Compound sort keys might speed up joins, GROUP BY and ORDER BY operations, and window functions that use PARTITION BY and ORDER BY.
- Interleaved:
- It gives equal weight to each column, or subset of columns, in the sort key.
- It improves performance for those queries that use different columns for filters.
- Compound:
Loading Data
Copy Command
- Loads data from S3, EMR, DynamoDB and remote host to a table.
- The COPY command can read from multiple data files or multiple data streams simultaneously.
- Perform the load operation in parallel.
- It can decrypt data and unzip files (gzip,izop,bzip2).
- Load from S3:
- Leverages MPP to read and load data in parallel from a file or multiple files in an Amazon S3 bucket.
- You can use a manifest file, a JSON-formatted file, that lists the data files to be loaded.
- Can load data files uploaded to Amazon S3 encrypted using server-side encryption, client-side encryption, or both.
- Load from EMR:
- Load data in parallel from an Amazon EMR cluster configured to write text files to the cluster’s Hadoop Distributed File System (HDFS) as fixed-width, character-delimited, CSV, or JSON-formatted files.
- Load from a Remote Host:
- Load data in parallel from one or more remote hosts, such as Amazon EC2 instances or other computers.
- It uses SSH to connect to the remote host and runs commands on the remote hosts to generate text output.
- Load from DynamoDB:
- Load a table with data from a single Amazon DynamoDB table.
Zero-ETL
- A fully managed solution that makes transactional and operational data available in Amazon Redshift from multiple operational and transactional sources.
- You don’t need to maintain an extract, transform, and load (ETL) pipeline.
- Sources are currently supported for zero-ETL integrations:
- Amazon Aurora MySQL
- Amazon Aurora PostgreSQL
- Amazon RDS for MySQL
- Amazon DynamoDB
Vacuuming tables
- Re-sorts rows and reclaims space in either a specified table or all tables in the current database.
- Amazon Redshift automatically sorts data and runs VACUUM DELETE in the background. This lessens the need to run the VACUUM command.
- Types of Vaccum command:
- FULL
- Sorts the specified table and reclaims disk space occupied by rows that were marked for deletion by previous UPDATE and DELETE operations. VACUUM FULL is the default.
- Doesn’t perform a reindex for interleaved tables.
- SORT ONLY
- Sorts the specified table without reclaiming space freed by deleted rows.
- Useful when reclaiming disk space isn’t important but re-sorting new rows is important.
- DELETE ONLY
- Reclaims disk space occupied by rows that were marked for deletion by previous UPDATE and DELETE operations.
- REINDEX
- Analyze the distribution of the values in interleaved sort key columns, then perform a full VACUUM operation.
- It takes significantly longer than VACUUM FULL because it makes an additional pass to analyze the interleaved sort keys.
- FULL
Streaming
- Streaming ingestion provides low-latency, high-speed data ingestion from Amazon Kinesis Data Streams or Amazon Managed Streaming for Apache Kafka to an Amazon Redshift provisioned or Amazon Redshift Serverless database.
- Data flows directly from a data-stream provider to an Amazon Redshift provisioned cluster or to an Amazon Redshift Serverless workgroup. There isn’t a temporary landing area, such as an Amazon S3 bucket
- MSK:
- Kinesis:
Unloading Data
Unload Command
- Use the UNLOAD with a SELECT statement to copy data from a database table to an S3 bucket.
- Text data can be unloaded in delimited or fixed-width format, regardless of the data format used to load it.
- It can also specify whether to create compressed GZIP files.
Redshift Data Sharing
- Share live data across Amazon Redshift clusters or with other AWS services.
- It lets you share live data without having to create a copy or move it.
- You can share database objects for both reads and writes across different Amazon Redshift clusters or Amazon Redshift Serverless workgroups within the same AWS account, or from one AWS account to another.
- Use Cases:
- Supporting different kinds of business-critical workloads
- Enabling cross-group collaboration
- Delivering data as a service
- Sharing data between environments
- Licensing access to data in Amazon Redshift (AWS Data Exchange)
- Types of Data Sharing:
- Standard – share data across provisioned clusters, serverless workgroups, Availability Zones, AWS accounts, and AWS Regions. You can share between cluster types as well as between provisioned clusters and Amazon Redshift Serverless.
- AWS Data Exchange – is a unit of licensing for sharing your data through AWS Data Exchange.
- AWS Lake Formation – share live data across AWS accounts and Amazon Redshift clusters through AWS Lake Formation-managed datashares.
- Must use RA3 nodes
- The performance of the queries on shared data depends on the compute capacity of the consumer clusters.
DBLINK (PostgreSQL Only)
- The DBLINK is an object created in the PostgreSQL instance.
- PostgreSQL performs queries remotely through extensions:
- The 1st extension is called the foreign-data wrapper, postgres_fdw.
- The 2nd extension is called dblink. The dblink function allows the entire query to be pushed to Amazon Redshift.
- Synthax:
CREATE EXTENSION postgres_fdw;
CREATE EXTENSION dblink;
CREATE SERVER foreign_server
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (host '<amazon_redshift _ip>', port '<port>', dbname '<database_name>', sslmode 'require');
CREATE USER MAPPING FOR <rds_postgresql_username>
SERVER foreign_server
OPTIONS (user '<amazon_redshift_username>', password '<password>');
Redshift Spectrum
- Efficiently query and retrieve structured and semistructured data from files in Amazon S3.
- There is no need to load the data into Amazon Redshift tables.
- Employ massive parallelism to run very fast against large datasets.
- Resides on dedicated Amazon Redshift servers that are independent of your cluster.
- Support a variety of data formats (XML not included)
- Support Gzip, Bzip2 and Snappy compression.
Data API
- Run SQL statements using the Data API operations with the AWS SDK.
- Asynchronous.
- Provides a secure HTTP endpoint.
- Removes the need to manage database drivers, connections, network configurations, data buffering, credentials, and more.
- Uses either credentials stored in AWS Secrets Manager or temporary database credentials.
- Limits:
- Max Query Duration: 24 hours
- Max Query Result Size: 100 MB
- Max Query Statement Size: 100KB
- Result Retention: 24 hours
Federated Queries
- Query and analyze data across operational databases, data warehouses, and data lakes.
- There is no need to load data to Redshift to query the data.
- Only read access.
- Can work with external databases in Amazon RDS for PostgreSQL, Amazon Aurora PostgreSQL-Compatible Edition, Amazon RDS for MySQL, and Amazon Aurora MySQL-Compatible Edition.
- It distributes part of the computation for federated queries directly into the remote operational databases to reduce data movement and improve performance.
System Tables and Views
- It contains information about how the system is functioning.
- You can query these system tables and views the same way that you would query any other database tables.
- Types of system tables and views:
- SVV views contain information about database objects with references to transient STV tables.
- SYS views are used to monitor query and workload usage for provisioned clusters and serverless workgroups.
- STL views are generated from logs that have been persisted to disk to provide a history of the system.
- STV tables are virtual system tables that contain snapshots of the current system data. They are based on transient in-memory data and are not persisted to disk-based logs or regular tables.
- SVCS views provide details about queries on both the main and concurrency scaling clusters.
- SVL views provide details about queries on main clusters.
UDF (User-defined Functions)
- Custom scalar user-defined function
- It is stored in the database and is available for any user with sufficient privileges to run.
- Three (3) types of UDF:
- Scalar Python UDFs:
- A Python program that runs when the function is called and returns a single value.
- Scalar SQL UDFs:
- A SQL SELECT clause that runs when the function is called and returns a single value
- Scalar Lambda UDFs:
- A custom function defined in AWS Lambda as part of SQL queries.
- The input and return data types can be any standard Amazon Redshift data type.
- Scalar Python UDFs:
Security
- Encryption at rest:
- Database encryption using KMS or HSM.
- Encryption in flight:
- SSL connection with clients via JDBC/ODBC.
- SSL connection between Amazon S3 or DynamoDB:
- Data in transit between AWS CLI, SDK, or API clients and Amazon Redshift endpoints is encrypted and signed.
- IAM Roles
- VPC/Security groups (Redshift is inside a VPC)
- Column-level access through GRANT statement.
- Row-level Security (RLS) through RLS policy
- Role-based Access Control (RBAC)
- Authentication in Query Editor:
- Username/Password
- IAM Identity Center (including SSO)
- Federated user (Temporary Credentials)
- Secrets Manager
Hands-On
Load Data from S3 using the Copy Command.
- Download the data that we will load to Redshift from this link: https://res.data.gov.hk/api/get-download-file?name=https%3A%2F%2Fwww.rvd.gov.hk%2Fdatagovhk%2F7.3.csv
- Upload the file to the S3 bucket:
- Create the ‘
hk_domestic_housing_sales‘ table in the Redshift Serverless:CREATE TABLE IF NOT EXISTS public.hk_domestic_housing_sales (Month VARCHAR(512), PrimarySalesNumber INT, PrimarySalesConsideration INT, SecondarySalesNumber INT, SecondarySalesConsideration INT);
- Using the Query Editor, use the following COPY command to load the data from S3 to the table:
COPY hk_domestic_housing_sales FROM 's3://mylinuxsite-dea-c01/source_data/hk_housing/hk_domestic_housing.csv' IAM_ROLE 'arn:aws:iam::<accountNo>:role/service-role/AmazonRedshift-CommandsAccessRole-20241004T110943'FORMAT AS CSV IGNOREHEADER 2;
- Verify the result:


Zero-ETL Integration (From MySQL RDS).
- Create an RDS Instance with a custom Parameter Group:
- Set the following parameters:
binlog_format=ROWbinlog_row_image=full

- Set the following parameters:
- Create an EC2 Instance on the same subnet as your RDS instance. You will need this EC2 instance to connect to the RDS instance and create the necessary database and table and load data in the RDS instance.
- Create a database and the table ‘
hk_domestic_housing_sales‘:CREATE TABLE IF NOT EXISTS hk_domestic_housing_sales (Month VARCHAR(512), PrimarySalesNumber INT, PrimarySalesConsideration INT, SecondarySalesNumber INT, SecondarySalesConsideration INT, PRIMARY KEY (Month));- Make sure that your table has a Primary Key.
- Update your Redshift Serverless enable_case_sensitive_identifier to true.
- $
aws redshift-serverless update-workgroup --workgroup-name default-workgroup --config-parameters parameterKey=enable_case_sensitive_identifier,parameterValue=true
- $
- Update the Redshift Serverless Resource Policy: Whitelist the RDS instance and the account owner.
- Create a Zero-ETL Integration in the RDS database:
- A corresponding Zero-ETL Integration entry will also be created in Redshift:
- When the Zero-ETL Integration is Active, create a Database in Redshift:
- Get the Integration ID:
SELECT integration_id FROM SVV_INTEGRATION limit 100
- Create a database:
CREATE DATABASE hk_housing FROM INTEGRATION '0c4ce7f4-78f0-460b-bb50-47ec3e783dc4'
- When the database is created, you will see that the table ‘
hk_domestic_housing_sales‘ will be synched from RDS to the Redshift database.
- And an empty table is created

- Load the data used in this hands-on to the RDS instance:
- Copy the file from S3 to the EC2 instance created previously:
- Load the CSV file into the table:
LOAD DATA LOCAL INFILE '/home/ssm-user/hk_domestic_housing.csv' INTO TABLE hk_domestic_housing_sales FIELDS TERMINATED BY ',' IGNORE 2 LINES;
- Copy the file from S3 to the EC2 instance created previously:
- Validate that the data from the RDS instance is synchronized to Redshift:







Redshift Spectrum.
- We will use the same test data as we used in this exercise.
- Create the external schema in Redshift:
create external schema athena_schema from data catalog database 'mylinuxsite-dea-c01' iam_role 'arn:aws:iam::<accountNo>:role/service-role/AmazonRedshift-CommandsAccessRole-20241004T110943'
- Create an external table in Redshift:
create external table athena_schema.hk_domestic_housing(Month VARCHAR(512), PrimarySalesNumber INT, PrimarySalesConsideration INT, SecondarySalesNumber INT, SecondarySalesConsideration INT )row format delimited fields terminated by ','stored as textfile LOCATION 's3://mylinuxsite-dea-c01/source_data/hk_housing/'table properties ('skip.header.line.count'='2')
- You can validate if the external table is created by looking at the Athena catalogue:
- Test to see if you can query the S3 file:

Use Data API to Query the hk_domestic_housing Table.
- We will use Secrets Manager for authentication:
- Create a Redshift secret:
- Create a Redshift secret:
- Execute a Data API query:
aws redshift-data execute-statement --region us-east-1 --secret arn:aws:secretsmanager:us-east-1::secret:mylinuxsite-dea-c01-XN7DpZ --workgroup-name default-workgroup --sql "select * from athena_schema.hk_domestic_housing limit 5;" --database hk_housing
- Get the result:
aws redshift-data get-statement-result --id 229b7544-b524-41e9-aa41-ae1a3820db39

Federated Query with RDS MySQL
- For this hands-on, we will use the same RDS MySQL database we used in the Zero-ETL Integration hands-on.
- Create the external schema in Redshift:
CREATE EXTERNAL SCHEMA IF NOT EXISTS mysql_federated_query_schema FROM MYSQL DATABASE 'redshiftetl' URI 'database-1.czuii808i5qm.us-east-1.rds.amazonaws.com' IAM_ROLE standard SECRET_ARN 'arn:aws:secretsmanager:us-east-1::secret:mylinuxsite-dea-c01-ub5VRI'
- Query the external schema from Redshift:

{kind=link}